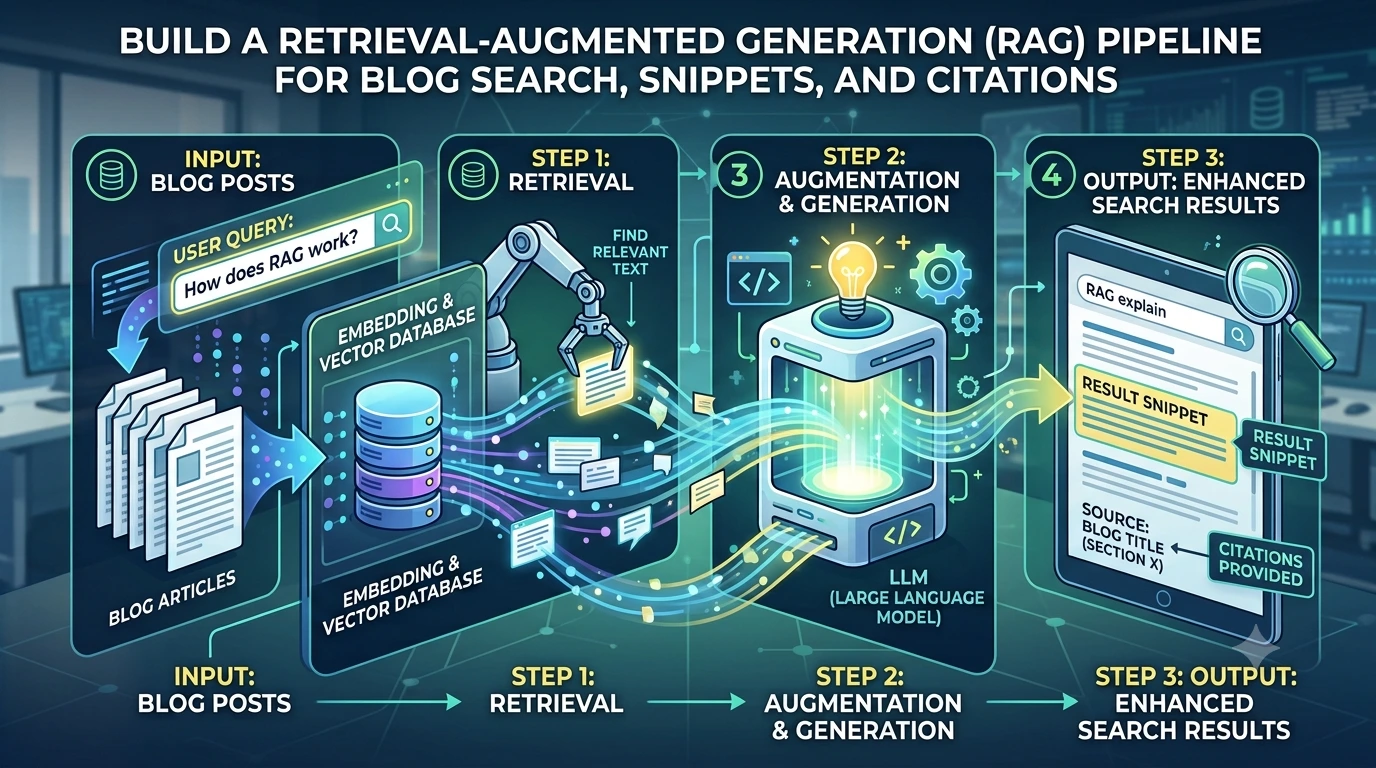
Search and on-page snippets are how readers find and trust your content. For modern blog platforms, Retrieval-Augmented Generation (RAG for blog content) combines semantic search with a language model to produce targeted search results, precise snippet text, and verifiable citations. This guide shows a production-ready architecture, practical chunking and embedding strategies, vector database tradeoffs (FAISS, Milvus, pgvector), caching and latency patterns, and pragmatic citation formatting so outputs are accurate and auditable.
Why RAG for blog content?
Traditional keyword search and simple excerpts struggle with long-form, topical content. RAG improves relevance by retrieving the most semantically similar passages and using a generation model to synthesize answers and snippets. For blogs, RAG enables:
- Higher-quality search snippets that read like human summaries.
- Contextual citations that point back to the exact paragraph or source.
- Better discovery across diverse formats (how-tos, interviews, docs).
High-level architecture
A production RAG pipeline has three stages: ingest (offline), index & store (nearline), and query-time (online). Keep each stage separate for reliability and scale.
- Ingest: crawl the blog, normalize HTML, chunk content, compute embeddings, and store fragments with metadata.
- Index & Store: add embeddings to a vector database and persist metadata in a fast document store (Postgres, DynamoDB) or object store.
- Query-time: perform ANN search, optionally hybrid-rank with lexical search, rerank, generate snippet with an LLM, attach citations, and cache results.
Ingest: chunking, metadata, and embeddings
Quality at ingest determines query-time accuracy and citation granularity. Key design choices:
Chunking strategies
Chunking controls how precise your citations can be and how coherent the model's context will be. Common approaches:
- Heading-aware chunks: split at H2/H3 boundaries to preserve topical coherence — good for how-to and tutorial posts.
- Sliding-window tokens: fixed token-size chunks (e.g., 200–500 tokens) with 20–30% overlap to preserve context across boundaries useful for long narrative posts.
- Semantically aware: use sentence or paragraph embedding similarity to merge small paragraphs into cohesive chunks.
Practical recommendations for blogs:
- Target 200–400 tokens per chunk for most LLMs; fewer tokens improve retrieval precision, more tokens reduce the number of vectors but can dilute relevance.
- Use 10–30% overlap to ensure the snippet generator sees surrounding context when needed.
- Keep chunk metadata: post_id, title, URL, heading path, character offsets, and a short anchor id for citation links.
Embedding model choice
Embedding model selection affects relevance, cost, and stability. Options:
- High-quality cloud embeddings (OpenAI, Anthropic): strong semantic recall, managed scaling, but ongoing cost.
- Open-source models (sentence-transformers, Mistral embeddings): lower cost and on-prem control; consider GPU requirements and maintenance.
Store model version with each vector to allow later reindexing if you upgrade embeddings.
Vector databases: FAISS, Milvus, pgvector and tradeoffs
Choose a vector database based on scale, operational overhead, and features you need.
- FAISS fast, flexible, great for single-node or carefully managed multi-node setups. Pros: low latency, many index types (IVF, HNSW). Cons: clustering/replication and persistence require engineering work.
- Milvus production-grade, distributed, supports hybrid search, snapshotting, and cloud operators. Pros: easier horizontal scaling, rich feature set. Cons: higher ops and memory footprint.
- pgvector built into Postgres, simple to operate, excellent for small-medium scale and transactional metadata joins. Pros: leverage existing Postgres infra. Cons: performance and scaling limits compared to FAISS/Milvus at large scale.
Decision factors:
- Scale (vectors count, qps)
- Latency SLOs
- Operational maturity and team expertise
- Need for hybrid search (vector + BM25)
Retrieval patterns: ANN, hybrid search, and reranking
At query-time, aim for a two-step retrieval to balance recall and precision:
- ANN retrieval: get top-K semantically similar chunks (K=50–200 depending on downstream).
- Optional lexical filtering: run a BM25 or SQL filter to ensure exact term matches or date ranges for freshness constraints.
- Reranking: use a cross-encoder or light model to rerank top candidates (e.g., top 20) for final precision.
This pattern gives strong recall while producing precise candidates for snippet generation and citation extraction.
Snippet generation and citation formatting
Generation prompts should focus the model on summarizing retrieved chunks and attaching verifiable citations. Two complementary outputs you want:
- Short UI snippet (one-liner for search results) — concise, 25–90 characters, highlights the answer.
- Expanded answer with citations — multi-sentence answer with bracketed citations that link back to the exact chunk anchor.
Prompt template (example)
System: You are a factual assistant. Use only the provided passages to answer. If the answer is not in the passages, say "I don't know". Always include citations in [post-title | anchor-id | char-start-char-end] format.
User: Question: {user_query}
Passages:
1. [{title}] {text}
2. [{title}] {text}
...
Instructions: Provide a short 1-sentence snippet for UI and a 2-3 sentence answer with inline citations. Do not invent facts. If multiple passages support the same fact, cite the most specific one.Example citation format to render in UI: [How I Built a Zero-Budget AI Publisher | anchor-3 | 1024-1189]. That maps to a URL like https://yourblog.com/post-slug#anchor-3 and character offsets for exact highlighting.
Caching and latency engineering
RAG involves multiple expensive steps; caching is essential for user experience and cost control.
- Query result cache: cache full response (snippet + answer + citations) for popular queries with a TTL (e.g., 1–24 hours) and invalidate on post updates.
- ANN warm caches: pre-warm ANN vectors for common queries or popular posts to reduce cold-start latency.
- Snippet micro-cache: store generated snippet text and citation mapping keyed by (post_id, chunk_id) so regenerated responses reuse fragments.
- Embedding cache: cache embeddings for recently updated posts and for repeated queries if you embed queries client-side.
Also use rate-limiting and batching for embedding/model calls. Batch embeddings during ingest and coalesce user queries where possible.
Evaluation: precision, citation accuracy, and UX metrics
Track both search and generation quality:
- Retrieval recall@K: how often the canonical answer appears in top-K candidates.
- Snippet precision: human-rated relevance of UI snippets.
- Citation accuracy: percent of generated facts that map to cited passages (requires periodic human review).
- Latency and cost per query: P95 latency and model API spend.
Operational concerns and monitoring
Production RAG needs observability:
- Track vector DB metrics (index size, query latency, memory usage).
- Log retrieval traces: query embedding, retrieved chunk ids, reranker scores, generation tokens.
- Alert on model failures, high generation hallucination rates (detected via QA or heuristics), or broken citation links when posts are edited or removed.
Example implementation (Python + FAISS + sentence-transformers)
This simplified snippet shows key steps: chunking, embedding, FAISS index creation, simple retrieval, and a prompt assembly for citation-aware generation. Replace model calls with your production embedding and generation APIs.
from sentence_transformers import SentenceTransformer
import faiss
# 1) Chunk texts (pseudo): chunks = [(post_id, title, url, anchor_id, text), ...]
# 2) Embed
model = SentenceTransformer('all-MiniLM-L6-v2')
texts = [c[4] for c in chunks]
embs = model.encode(texts, convert_to_numpy=True)
# 3) Build FAISS index
d = embs.shape[1]
index = faiss.IndexHNSWFlat(d, 32)
index.hnsw.efConstruction = 200
index.add(embs)
# 4) Query-time
q_emb = model.encode([user_query])[0]
D, I = index.search(q_emb.reshape(1, -1), k=20)
retrieved = [chunks[i] for i in I[0]]
# 5) Assemble passages for generation
passages = "\n\n".join([f"[{r[1]}] {r[4]}" for r in retrieved])
prompt = f"Question: {user_query}\n\nPassages:\n{passages}\n\nAnswer concisely and cite passages."In production, add a cross-encoder reranker for the top-N (e.g., using a lightweight transformer), and call your LLM with the assembled prompt, returning structured citations that map back to anchors and offsets.
Best practices checklist
- Chunk by headings with token-size fallback; include 10–30% overlap.
- Store rich metadata (post id, URL, anchor, char offsets) for each chunk.
- Choose vector DB by scale: FAISS for low-ops/high-perf, Milvus for distributed needs, pgvector for simple integration.
- Use ANN + lexical hybrid retrieval and rerank results before generation.
- Always include explicit citation formatting in generation prompts and persist mapping from citation token to source anchor.
- Cache results at multiple layers and invalidate on content updates.
- Instrument retrieval and citation accuracy metrics and perform periodic human audits.
Make the retrieval layer auditable: every generated fact should point to a stored chunk with a stable URL/anchor and character offsets so editors can verify or correct outputs.
Conclusion
RAG for blog content unlocks better discovery, more useful snippets, and credible, auditable citations — but achieving that in production requires careful decisions across chunking, embeddings, vector DB selection, caching, and prompt design. Start with a small-scale index, measure retrieval recall and citation accuracy, and iterate: upgrade embeddings, add rerankers, and introduce caches only after observing query patterns. With the right architecture, RAG transforms a blog from a content repository into a responsive knowledge surface that users can trust.
Frequently Asked Questions
What chunk size is best for RAG on blog content?
Aim for 200–400 tokens per chunk with 10–30% overlap. Use heading-aware chunking where possible and fall back to token-based chunks for long sections. Smaller chunks increase citation precision; larger chunks reduce vector count but may dilute relevance.
Should I use FAISS, Milvus, or pgvector for a blog-scale vector DB?
Choose FAISS for high-performance single-node setups with engineering ops to handle persistence and replication. Choose Milvus for distributed, production-ready features and easier horizontal scaling. Choose pgvector for small-to-medium scale where you want to leverage existing Postgres infrastructure and simplified operations.
How do I prevent the LLM from hallucinating facts not in my blog?
Constrain the model with a strict prompt that instructs it to use only provided passages and to respond 'I don’t know' when necessary. Include passage citations in the output and prefer retrieval + rerank before generation to ensure supporting evidence exists in the retrieved chunks. Regularly audit citation accuracy with human reviews.
What caching strategies reduce cost and latency for RAG?
Use multi-layer caching: query result cache for popular queries, snippet micro-cache for generated snippets keyed by chunk, embedding cache for repeated items, and ANN warm caches for high-traffic vectors. Invalidate caches on content updates and throttle model calls with batching.
How do I format citations so they’re auditable?
Attach structured citations containing post title, anchor ID, and character offsets, e.g., [Post Title | anchor-3 | 1024-1189]. Map each citation to a stable URL like https://yourblog.com/post-slug#anchor-3 so editors can verify the exact text span used by the model.