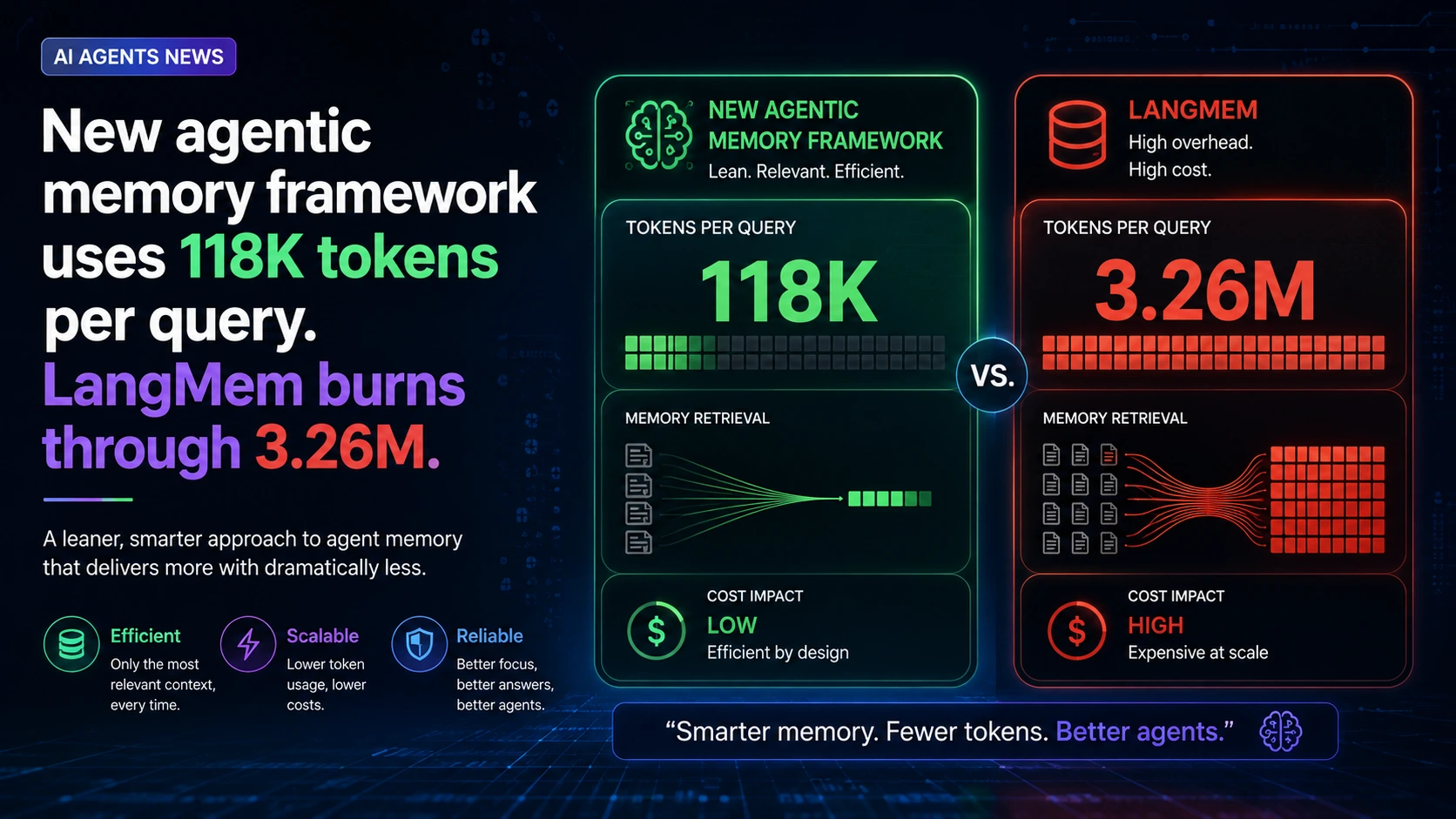
Long-horizon reasoning reveals a predictable bottleneck: context windows fill quickly and retrieval pipelines return noise more often than signal. A recent effort from researchers at the National University of Singapore proposes MRAgent, an agentic memory framework that abandons the static "retrieve-then-reason" approach. The headline comparison is stark — the new agentic memory framework uses 118K tokens per query, while LangMem-style approaches can burn through 3.26M tokens for similar long-horizon tasks.
Why token counts matter for long-horizon agents
Tokens are the unit that determines model context, latency, and cost. When an agent needs to reason across months of interaction, naive retrieval strategies often bring back large swaths of context—many irrelevant items along with a few useful facts. That both wastes tokens and muddies the prompt, producing lower-quality outputs despite larger token consumption.
Reporting token counts — for example, 118K tokens per query for MRAgent versus 3.26M for LangMem — is useful because it forces designers to measure the real operational cost of memory strategies, not just theoretical recall. Fewer tokens per query usually translates to lower latency, cheaper API bills, and cleaner prompts for the reasoning model. But lower token use is only valuable when it preserves or improves relevant signal.
What MRAgent changes about the memory loop
MRAgent reframes memory as an agentic component rather than a static store. Instead of running a large retrieval step up front and dumping everything into the reasoning context, MRAgent delegates memory management to an active process that selects, consolidates, and prepares what the reasoner actually needs.
- Selective rehearsal: the agent maintains a smaller working set of memories tuned to the current objective instead of returning all candidates from an index.
- On-demand expansion: additional context is fetched only when a reasoning step explicitly requires it, rather than preloading everything.
- Incremental summarization: memories are compressed or abstracted into concise representations that fit a limited context window.
- Feedback-driven refinement: the reasoner and memory manager exchange signals about what was useful, letting the memory agent re-rank or prune entries over time.
Those behaviors explain why an agentic framework can achieve a working context that consumes ~118K tokens per query: the pipeline intentionally limits what reaches the reasoning model while preserving the high-value pieces.
How LangMem-style pipelines end up using millions of tokens
LangMem and similar approaches aim for high recall by retrieving large amounts of raw context and relying on the language model to filter and synthesize. That strategy often looks efficient on paper — more data should help — but in practice it floods the context window with redundant or low-relevance material. The result is heavy token usage (the 3.26M figure) and diminishing returns: added tokens increase cost and latency while degrading prompt clarity.
Key failure modes include overlapping chunks, weak reranking, and a lack of summary consolidation. If retrieval returns dozens of overlapping documents or raw transcripts, every query will re-send that redundancy to the model.
Practical implications for teams building long-horizon agents
Whether you adopt an agentic memory design or improve an existing RAG pipeline, the following practices translate the high-level trade-offs into actionable work:
- Measure tokens per query. Instrument end-to-end requests (retrieval + prompt + response) and report median and 95th-percentile token counts. Track how those change as your memory policies evolve.
- Introduce a memory manager. Separate concerns: index storage, candidate retrieval, and a lightweight controller that decides what to push to the reasoner. The controller can use a smaller model to re-rank and summarize candidates before costly LLM calls.
- Use hierarchical summaries. Store long histories as layered summaries: raw events → session summaries → consolidated abstractions. Pull the smallest representation that answers the query, only expanding when needed.
- Implement incremental retrieval. Start with a compact, high-precision context. If the reasoner indicates uncertainty or requests more evidence, fetch additional supporting items in a second step rather than loading everything at once.
- Rerank with cheap models. Use embedding similarity for coarse filtering and a small instruction-tuned model for precision reranking before assembling the prompt for the main model.
- Instrument retrieval noise. Track the ratio of retrieved items that are actually cited or used in the final response. Reduce noise by tightening similarity thresholds or improving metadata filters.
- Budget tokens strategically. Define a token budget per query and hold the memory stack to it. Prefer concise, task-oriented summaries over long verbatim passages.
Concrete workflow example
Imagine a customer-support agent that reasons over a year of interactions. A practical agentic workflow looks like this:
- Query arrives; embeddings-based retrieval returns the top 200 candidates (coarse filter).
- A lightweight reranker (small LLM) compresses those to the top 10 task-relevant summaries (consolidation).
- The memory manager assembles a 10–20KB prompt containing: a short user history summary, 3–5 supporting items, and the current objective.
- The main reasoning model runs on that compact prompt. If it needs more evidence, it issues a secondary fetch controlled by the memory agent.
That pipeline keeps the primary model's context focused and predictable, and it is the sort of design that produces the lower token consumption reported for MRAgent.
Trade-offs and when LangMem still makes sense
Agentic memory reduces token waste but adds system complexity: a memory controller, additional models for reranking and summarization, and extra engineering for feedback loops. LangMem-style approaches are simpler to implement and can be effective when histories are short, the retrieval index is high quality, or when the application tolerates higher latency and cost.
Choose agentic designs when long histories, repeated interactions, or multi-step workflows require precise, context-aware reasoning. If you have limited engineering bandwidth and short-horizon tasks, a well-tuned RAG with careful chunking can still be acceptable.
How to evaluate memory strategies in your project
Set up a small benchmark suite that reflects your real tasks and measure a few practical metrics:
- Tokens per query (median, p95) — truthfully reports cost and practical window usage.
- Retrieval precision — fraction of retrieved items used or cited in the final response.
- Response quality — domain-specific metrics (task success rate, factuality, or human-rated quality).
- Latency and compute cost — end-to-end time and monetary cost per query.
Run A/B comparisons: keep the same downstream model and evaluate MRAgent-style preprocessing versus a LangMem-style heavy retrieval. That isolates whether token-frugal memory management preserves or improves quality for your use case.
Practical checklist to start moving to agentic memory
- Instrument your pipeline to measure tokens per query across components.
- Add a lightweight reranker and summarizer ahead of the main model.
- Design a memory consolidation policy (time-based, importance-based, or user-driven).
- Define token budgets and fallbacks for low-confidence situations (e.g., fetch more evidence when needed).
- Set up periodic pruning or rehearsal to keep the working set relevant.
Token economy is part engineering, part product design: measure what you send to the model, control how it is prepared, and make decisions based on the marginal value of extra context.
Where this matters most
Agentic memory is especially valuable for applications that need sustained, contextualized decision-making: personal assistants with long user histories, research agents tracking evolving projects, and multi-step automation that revisits earlier steps. For one-off queries or tightly scoped tasks, the overhead may not be worth it.
Next steps for teams
Begin by benchmarking current token usage and retrieval noise. If your median or tail tokens-per-query look large or your retrieval precision is low, invest in a small memory controller experiment: add a reranker and a summarizer and compare downstream quality and cost. Over time, move toward layered summaries and feedback-driven pruning to approach the token efficiency reported for agentic frameworks like MRAgent while avoiding the runaway costs associated with heavy LangMem-style retrieval.
Frequently Asked Questions
What does it mean that the new agentic memory framework uses 118K tokens per query?
It means the end-to-end prompt and retrieval context sent to the reasoning model averages about 118,000 tokens per query — a measured, operational metric showing how much context actually reaches the model. Lower token counts imply lower latency and cost if quality is preserved.
Why does LangMem consume 3.26M tokens for similar tasks?
LangMem-style pipelines often retrieve large amounts of raw context with high redundancy and rely on the main model to filter it. That approach sends far more tokens to the model, inflating cost and introducing noise, which explains the higher token consumption figure.
Does using fewer tokens always mean better performance?
No. Token efficiency matters only when relevant signal is preserved. The goal is to maximize useful information per token — reduce noise while keeping or improving task-specific quality.
What practical first step should teams take to adopt agentic memory ideas?
Start by instrumenting tokens-per-query and retrieval-precision metrics. Then add a lightweight reranker/summarizer before the main model to compress context and compare downstream quality and cost.
When is LangMem still a reasonable choice?
If your tasks are short-horizon, histories small, or engineering resources limited, a well-tuned RAG/LangMem approach can be simpler and sufficient. Agentic memory pays off primarily for long-lived user histories and repeated interactions.